本文共 1824 字,大约阅读时间需要 6 分钟。
06 - 10:Clare Corthell, Drew Conway, Kevin Novak, Chris Moody, Erich Owen
- Clare Corthell “开源数据科学高手”课程创建者 教育经历:斯坦福大学·学士 职业经历:Mattermark数据主管

- 与众不同之处
在斯坦福的专业是科学技术与社会学,完全是靠自学掌握了数据科学。是一个主动学习能力非常强,很有恒心的人。
- “开源数据科学高手”地址(注:好资料!)
- 推荐《集体智慧编程》一书
“每一次我打开它的时候,总有一些新的知识会跳出来,并且我也越来越理解有关整合用户想法的东西。那本书成了我的基石,我用它来衡量我取得的进步。它绝对是数据科学家的“圣经”。”
- Drew Conway 《Machine Learning for Hackers》共同作者 数据科学韦恩图创建者 教育经历:计算机科学与政治科学双学位,纽约大学政治学博士 职业经历:IA Ventures,Project Florida数据主管

- 数据科学韦恩图
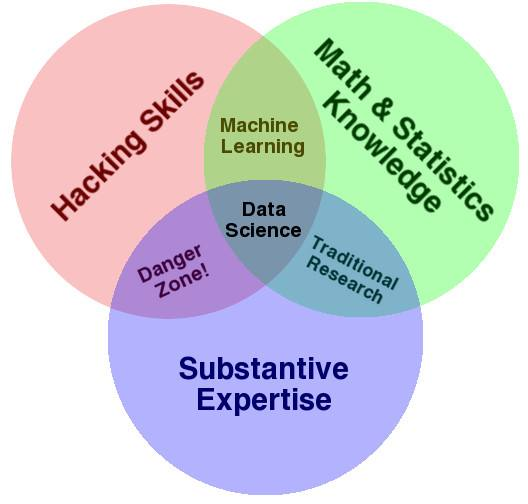
- 为什么要读博士?
遇到了职业天花板。在纽约读博期间创建了data kind,并与Mike Dewar和Hilary Mason结识。
- 讲故事的能力
“其实大部分数据科学家所做工作中的一大部分都不是数据整理或者建模或者编程,而是一旦你做出了一个结果,你必须要想办法将结果解读给那些完全不具备看懂这个图所必需的技能的人听,例如那些做商业决定或者工程决策的重要人物。”
- 比较纽约和硅谷
纽约资源配置更加集中。
- 选择Python还是R?
“他们想要学习Python或者R但是不确定哪一个更好,我告诉他们不要犹豫,直接选一个深深地扎下去就行。”(注:我觉得还是Python生态好)
- Kevin Novak 教育经历:密歇根州立大学核物理博士,研究方向回旋加速器,主要工作是用统计方法去对核交互作用中的理论模型建模,然后用加速器里跑出来的数据来验证模型是否正确。 职业经历:Uber数据科学主管

- Uber数据团队构成
Uber数据团队中的每个人几乎都是来自非传统的行业背景的。他们过往差不多都在做各自不同的东西。
- 数据科学包括什么?
其中一个概念就是“大数据”,海量的数据经过处理分析被提取出数学化的结论。另一个概念就是高度专业化的预测建模。
- 数据科学必备技能
数学、统计学、计算机科学。
- 数据科学的前景
传统的数据领头羊公司专注还是社交数据,Uber用于解决物流问题的方法也可以推广到一切统筹问题。其它的还包括,分析基因组、健康领域。
- Chris Moody 教育背景:加州理工学士,本科物理学;加州大学圣克鲁斯分校博士,研究方向计算天文学(注:Chris从本科开始就与天文学打交道)。 职业经历:Square,Stitch Fix。

- 自学
“我的一大部分软件工程技术,甚至于整个计算机科学知识,都是完全自学的。我没有上过任何那个领域的正式课程。”
- 数据科学意味着什么?
“总体上来说,它意味着你对数据进行计算的方式,能够有能力对数据进行解读,对数据进行建模,并且最重要的就是,有能力用数据的内在意义去与别人沟通交流。”
数据科学大概可以分为两个板块:描述分析和预测分析。预测分析型数据科学家需要一些有关于机器学习的知识,而描述型的数据科学家应该需要一些统计学知识。
- 相比于优秀的数据科学家,卓越的数据科学家具有怎样的素养?
“我觉得可能是沟通交流方面的技巧。你必须要有能力去将你做的东西讲出来给别人听。”
“编程能力不会是最重要的能力。”
- Erich Owen 教育经历:Albion文科学校学士·数学物理(注:原书这里翻译成立自由艺术学校,囧),布朗大学硕士·应用数学 职业经历:Quid、Newsle、Facebook

- 大学时代最应该做的事
去做实实在在的东西,建立网站或者完成一些项目,写更多的程序。
- 在Facebook的工作
主要工作是搭建全栈系统,也做机器学习。
- 相较于一般的数据科学家,是什么品质让那些卓越的数据科学家得以脱颖而出?
扎实的编程基本功和系统的思维能力是最为重要的。
- 数学的作用
举例,低通路的过滤器去过滤这一批数据,“数模转换”概念对于研究社交数据的作用;奇异值分解;随机映射。
- 关于学习
“我觉得根据我多年的本科和研究生经历,我做的最为有用的事情就是我一直在不断地在学习,并且我是为了求知而学习,因为我真的对于学习很有兴趣。”
转载地址:http://rszox.baihongyu.com/